Fargo: A joint framework for faz and rv segmentation from octa images
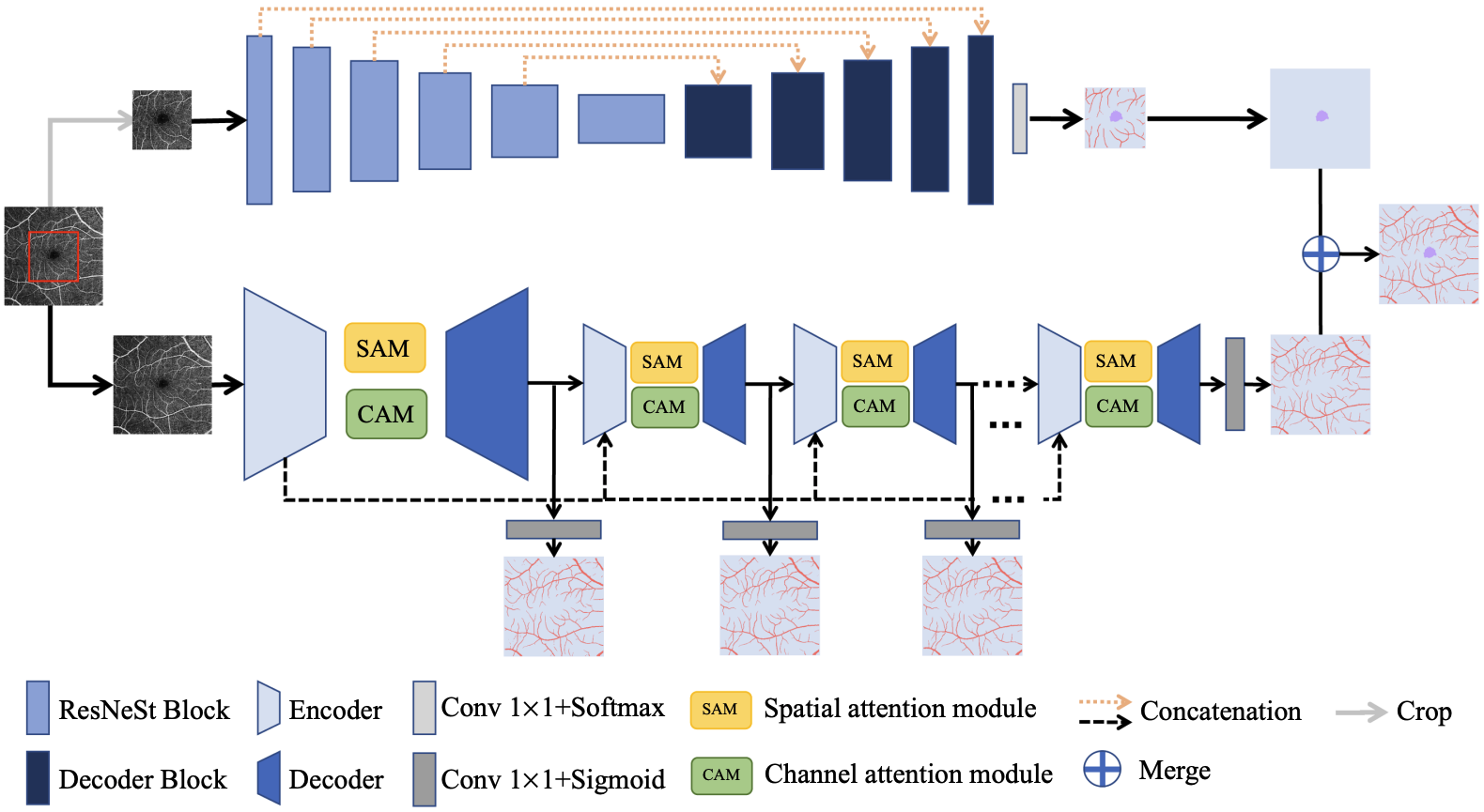
Optical coherence tomography angiography (OCTA) is a recent advance in ophthalmic imaging, which provides detailed visualization of two important anatomical landmarks, namely foveal avascular zone (FAZ) and retinal vessels (RV). Studies have shown that both FAZ and RV play significant roles in the diagnoses of various eye-related diseases. Therefore, accurate segmentation of FAZ and RV from OCTA images is highly in need. However, due to complicated microstructures and inhomogeneous image quality, there is still room for improvement in existing methods. In this paper, we propose a novel and efficient deep learning framework containing two subnetworks for simultaneously segmenting FAZ and RV from en-face OCTA images, named FARGO. For FAZ, we use RV segmentation as an auxiliary task, which may provide supplementary information especially for low-contrast and low-quality OCTA images. A ResNeSt based encoder with split attention and ImageNet pretraining is employed for FAZ segmentation. For RV, we introduce a coarse-to-fine cascaded network composed of a main segmentation model and several small ones for progressive refining. Spatial attention and channel attention modules are utilized for adaptively integrating local features with global dependencies. Through extensive experiments, FARGO is found to yield outstanding segmentation results for both FAZ and RV on the OCTA-500 dataset, performing even better than methods that utilize 3D OCTA volume as an extra input.